24夏季实训01:排序(Sort)
经典排序算法的优化及其测试
2023-2024 夏季学期《计算机程序设计实训》课程报告
(计算机工程与科学学院)
摘 要 本文主要研究常用的经典排序算法在不同的数据规模,数据类型,数据分布的情况下的运行 效率,并将通过对冒泡排序、选择排序、快速排序三种经典算法的优化研究,探索不同排序算法在不同数 据场景下的表现。对所得出的数据,将以图表的方式做出具体分析。
关键词 排序;优化算法;算法评析;
Optimization And Testing Of Classical Sorting Algorithm
2023-2024 SUMMER SEMESTER “COMPUTER PROGRAMMING TRAINING”
COURSE REPORT
(School of Computer Engineering and Science)
Abstract This paper mainly studies the efficiency of commonly used classical sorting algorithms in the case of different data scale, data type and data distribution, and explores the performance of different sorting algorithms in different data scenarios by optimizing three classical algorithms, namely bubble sorting, selection sorting and quick sorting. The resulting data will be analyzed concretely in the form of charts.
Key words Sorting; Optimization algorithm; Algorithm evaluation;
1.引言
排序是通过元素间的比较、交换或移动,使元素按某种顺序重新排列的过程。这是数 据结构与算法基础中非常重要的部分。不同的排序算法意味着在排序过程中对元素操作策 略的差异。了解并实现排序算法,并对其进行优化,有助于深入理解算法的时空复杂度, 从而加深对数据结构与算法基础的掌握。
因此,在此次实训中,我们小组对三种常见的排序算法——冒泡排序、选择排序和快 速排序——进行了实现、优化和深入分析。在研究过程中,为应对不同输入情况,我们还 对不同存储方式的 C-字符串的排序进行了实现与分析,这也加深了我们对指针的理解。本 文将详细阐述本次实训中我们小组的工作内容。
2. 经典排序算法的研究
2.1 排序算法的实现、优化及测试
2.1.1 冒泡排序(Bubble Sort)的实现、优化及测试
A.基础冒泡排序实现
冒泡排序是一种比较简单的直观算法,它从第一个数字开始重复地去访问要排序的数 列,一次比较两个相邻的数字,找出这两个数字之间的大小关系,并根据要求看是否要交 换这两个数字。将数组里的所有数字比较过一次后,最后的一个数字一定是最大或最小 的,那么再次进行比较的时候,所比较的次数就会减一次,直到没有再进行交换,那么该 数列也就已经冒泡排序完成了。
实现步骤:
步骤 1:首先比较相邻两个元素。如果当前数字比第二个大,就将这两个数字交换。
步骤 2:比较下一个数字,对每一对相邻元素作同样的工作,从开始第一对到结尾的 最后一对,每次比较的数字是数组下标+1 的数字,这步做完后,最后的元素一定是这些数 字里面的最大值 步骤 3:重复以上的步骤,每次所比较的数字除掉最后一个,比较的次数-1。
步骤 4:每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
基础冒泡排序代码如下:
1 | void I_Bubble(int *a, int size) { |
B. 优化:去除不必要的比较
冒泡排序的时间复杂度:
快假设我们只冒泡排序 4 个数,也就是我们需要排序 3 趟,第一趟比较俩俩比较 3 次,第二趟 2 次,第三趟 1 次,合起来一共 3+2+1=6 次。按照这样的算法,如果我们要冒 泡排序 N 个数,也就是我们需要冒泡排序 N-1 趟,即我们一共要比较(N-1)+(N-2)+(N- 3)+(N-4)+…+3+2+1=(N-1)(1+N-1)/2=N(N-1)/2。所以根据时间复杂度的算法,冒泡排序法的 时间复杂度为 O(N^2)。
目前,比较好的方法是引入一个额外变量 flag。它的思想是:在两个数据没有交换时 提前结束这一循环。
实现引入 flag 的代码如下
1 | void I_Bubble(int *a, int size){ |
C. 算法分析与测试 算法分析
1. 空间复杂度分析
—————————————————————————————————————
由于所有冒泡算法都是在地址上进行数据操作,因此算法本身并没有产生额外的内 存空间,因此,空间复杂度为(1)。
2. 稳定性分析
a)基础冒泡排序 使用冒泡排序的过程中,较小的数据总是不断的被移动到前面,在排序过程中数 据前部会形成有序数列,按照基础冒泡排序的设计,前部的有序数组不会被再次排 序,因此基础冒泡排序是稳定排序。
b)flag 冒泡排序 由于引入的 flag 只作为判断数据是否有序的变量,并没有对数据进行额为操作,因 此基于基础冒泡排序的 flag 冒泡排序是稳定排序。
3. 时间复杂度分析
不论在什么情况下,基础冒泡排序的时间复杂度都是O(n 2),但在加入 flag 优化的 判断下,基础冒泡排序在数据已经有序时能自动跳出循环,使得在处理顺序或基本有 序的数据时能达到O(n)的时间复杂度。
测试数据
a. 处理不同分布方式整型(int)数据的测试结果如下图 2.1.1:
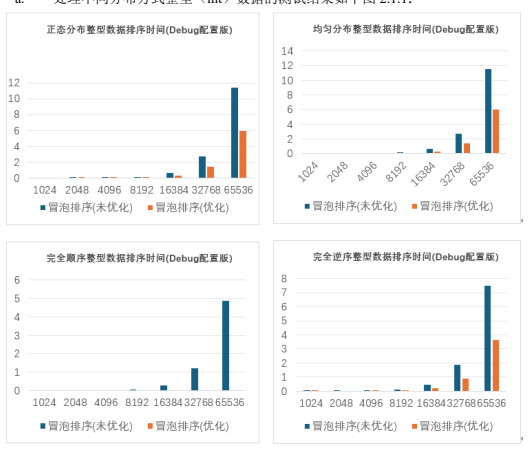
对整型数据测试结果的分析:对于均匀分布、正态分布和完全逆序的整型数据,flag 优化 版用时是基础版的 0.5 倍左右。当处理完全顺序的整型数据时,由于只要进行一次循环, 所以 flag 优化版用时远小于基础版。
对浮点型数据测试结果的分析:对于均匀分布和正态分布的浮点型数据,flag 优化版用时 是基础版的 0.5 倍左右;处理完全逆序的浮点型数据时,flag 优化版用时稍长,约为基础 版的 0.75 倍。当处理完全顺序的浮点型数据时,由于只要进行一次循环,所以 flag 优化版 用时远小于基础版。 c.处理正态分布结构体类型(Score)数据的测试结果如下图 2.1.3:
b.处理不同分布方式浮点型(double)数据的测试结果如下图 2.1.2:
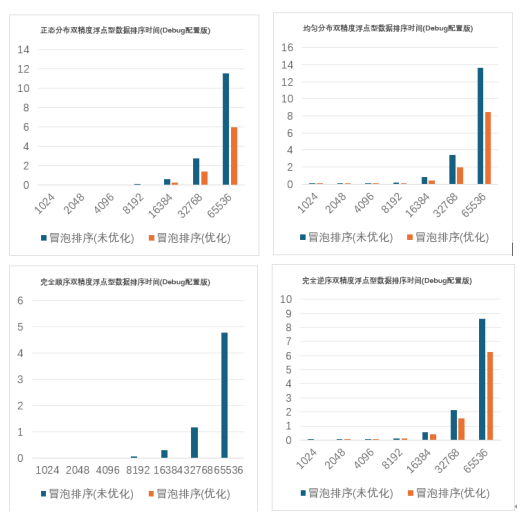
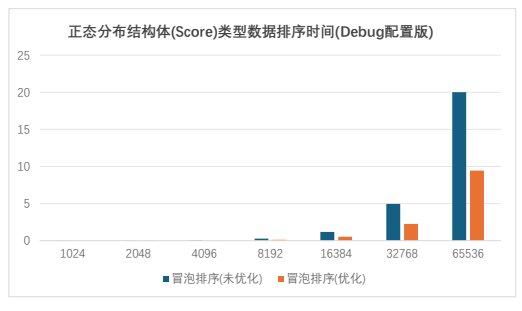
图 2.1.3
对结构体类型数据测试结果的分析:
在对正态分布结构体类型数据的测试过程中发现,flag 优化版用时约为基础版冒泡排序 的 0.45 倍。由于结构体类型数据较为复杂,所以比起整型和浮点型数据,flag 优化版的优 势更加明显。
2.1.2 快速排序(Quick Sort)的实现、优化及测试
A.基础快速排序实现
快速排序通过多次比较和交换来实现排序,在排序过程中首先在数组中任意选取一个 数作为基准,然后将所有小于等于它的数放在它的左边,将所有大于等于它的数放在它的 右边,在对所有数都完成了一次比较之后,一次快速排序便完成了,这之后将这个数组以 基准为界分成两个数组再分别进行快速排序,多次递归后便得到了一个完全有序的数组。
实现步骤:
步骤 1:选取一个基准(一般为数组的第一个或最后一个元素)
步骤 2:分别标记数组的第二个元素和最后一个元素为头和尾 步骤 3:头标记向右跨过所有小于等于基准的元素停在第一个大于基准的元素,尾标 记向左跨过所有大于等于基准的元素停在第一个小于基准的元素 步骤 4:将被头和尾标记的元素交换 步骤 5:重复步骤 3-4,直到头标记和尾标记均在同一个元素上,将该元素和基准交 换,并以基准为界分为两个数组 步骤 6:分别对两个数组重复步骤 1-5 基础快速排序代码如下:
1 | void I_Qsort(int *a, int size) // 快速排序 |
B. 优化 1:优化快速排序基准的选择
快速排序的运行时间与划分是否对称有关。最坏情况下,每次划分过程产生两个区域 分别包 k 含 n-1 个元素和 1 个元素,其时间复杂度会达到 O(n^2)。在最好的情况下,每次 划分所取的基准都恰好是中值,即每次划分都产生两个大小为 n/2 的区域。此时,快排的 时间复杂度为 O(nlogn)。所以基准的选择对快排而言至关重要。
目前,比较好的方法是使用三数取中选取基准。它的思想是:选取数组开头,中间和 结尾的元素,通过比较,选择中间的值作为快排的基准。其实可以将这个数字扩展到更大
(例如 5 数取中,7 数取中等)。这种方式能很好的解决待排数组基本有序的情况,而且选取 的基准没有随机性。
-—————————————————————————————————————
————————————————————————————————————
实现三数取中的代码如下
1 | void I_swap(int *a, int *b) { // 交换函数 int temp = *a; *a = *b; *b = temp; |
—————————————————————————————————————
C. 优化 2:序列长度达到一定大小后,使用插入排序
当快排达到一定深度后,划分的区间很小时,再使用快排的效率不高。当待排序列的 长度达到一定数值后,可以使用插入排序。由《数据结构与算法分析》(Mark Allen Weiness 所著)可知,当待排序列长度为 5~20 之间,此时使用插入排序能避免一些有害的退 化情形,在划分到很小的区间时,里面的元素已经基本有序了,再使用快排,效率就不高 了。所以,在结合插入排序后,程序的执行效率有所提高。
使用插入排序优化后的代码如下:
1 | void I_InsertSort(int* a, int n) //插入排序(用于优化数据量较小时的快速排序) |
D. 算法分析与测试
算法分析 1. 空间复杂度分析 由于所有快速算法都是在地址上进行数据操作,因此算法本身并没有产生额外的 内存空间,因此,空间复杂度为(1)。
2. 稳定性分析
对于快速排序,如果让其对一个有着重复数据的数组进行排序,若所选的基准正 好为重复数据的一个,则他们的相对顺序会被打乱,所有快速排序试一个不稳定的排 序算法。
3. 时间复杂度分析
在每次取到的基准都能将数组平分,也就是最理想的情况下,确认第 1 个数 要遍历 n 个数,确认第 2 个数和第 3 个数需要遍历 n/2 个数,确认第 4、5、6、7 个数各需要遍历 n/4 个数。将分段缩小到 1,则需要分 x 次,即 1=n/(2^x), x=log2n,即一共有 log2n 层将每一层都近似得看作遍历 n 个数,则总遍历个数为 n*log2n,即最优情况时间复杂度为 O(nlogn)。
而如果每次取到的基准都是数组中的最大值或最小值,也就是最差情况下, 确认第 1 个数要遍历 n 个数,确认第 2 个数要遍历 n-1 个数,以此类推,等差求 和得遍历个数为 n*(1+n)/2,时间复杂度为 O(n^2)。
测试数据
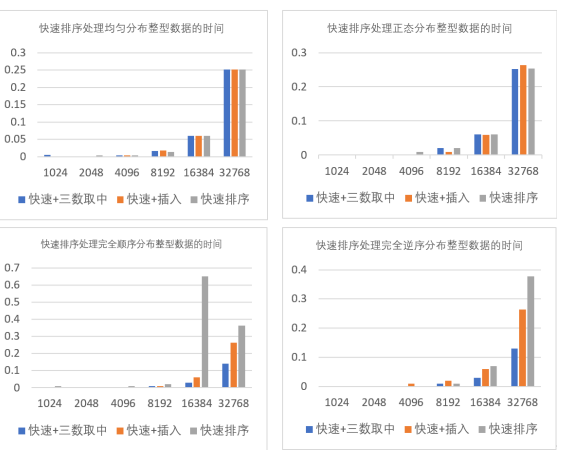
a. 处理不同分布方式整型(int)数据的测试结果如下图 2.1.4:
图 2.1.4
对整型数据测试结果的分析:
对于均匀分布和正态分布的整型数据,两种优化方案与基础的快速排序算法运行时间 差距不大,但当处理完全顺序分布以及完全逆序分布的数据时,两种优化方案在运行时间 上明显表现出优于基快速排序算法的性能,尤其是快速排序+三数取中法的优化方案相比 于基础快速排序算法可以实现大幅减少运行时间。
b.处理不同分布方式浮点型(double)数据的测试结果如下图 2.1.5:
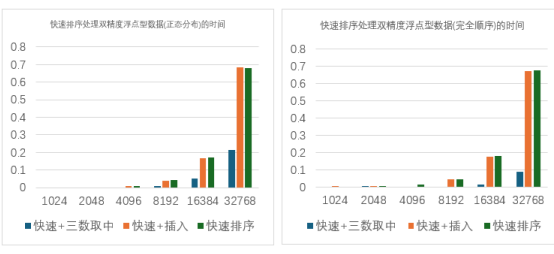
图 2.1.5
对浮点型数据测试结果的分析:

在对浮点型数据的测试过程中发现,快速排序+插入排序的优化方法并没有在基础的排 序算法上有明显的提高,但是三数取中法的优化方案仍然在浮点数的测试中表现出优秀的 性能,相比于基础快速排序算法可以实现大幅减少运行时间。
2.1.3 选择排序(Selection Sort)的实现、优化及测试 A.基础选择排序实现
选择排序是最为简单实现的代码之一,以从小到大排序为例,首先需设立一个 min 以 记录目前最小元素的下标,以第一个地址为初始位置,依次与后续地址的元素值进行比 较,若比 min 所在地值更小则进行交换,全部比较完成后则交换对应初始位置与 min 的内 容,然后以第二个数为初始位置开始进行第二轮比较,以此类推,直至排序完成得到一个 完全有序的数组。
实现步骤:
步骤 1:设置一个最小值坐标 min,以及两个标记 i=0,j 步骤 2:令 min=i,j=i 步骤 3:如果 min 所在位置的值大于 j 所在位置的大小便令 min 等于 j,j++
步骤 4:循环进行步骤 3 直到 j>=数组长度 步骤 5:如果 min 不等于 i,便交换 i 与 min 所在位置的值,i++
步骤 6:如果 i<数组长度,则进行步骤 2 基础选择排序代码如下:
1 | void SelectDouble(double* a, int size) { // 选择排序 double t; int i, j, min = 0; for (int i = 0; i < size; i++){ |
B. 优化:优化选择排序在遍历中比较值的个数
在刚刚的基础版中,每次只能进行一个元素的交换,不妨在设置一个最大值 max 一同 进行运算,减少遍历次数,只需遍历一半便可达到目标。
1 | void NewSelectDouble(double* a, int size) // 优化选择排序 |
C. 算法分析与测试
算法分析 1. 空间复杂度分析 由于所有快速算法都是在地址上进行数据操作,因此算法本身并没有产生额外的内存 空间,因此,空间复杂度为(1)。
- 程序的稳定性
(1) 基础选择排序 该算法在选择最小值的过程中使用了交换操作,如果遇到相同的值,可能会改变他们 在数组中的相对位置,因此该算法不是稳定的的排序算法.
(2) 优化选择排序
该算法在选择最小值和最大值的过程中使用了交换操作,如果遇到相同的值,可能会 改变他们在数组中的相对位置,因此该算法不是稳定的的排序算法
3. 时间复杂度
(1) 基础选择排序 根据程序观察可得为双重循环,分别循环 n 次,n-i 次.此时时间复杂度为 O(n × n/2 × 1),即 O(n^2)。
(2) 优化选择排序
根据程序观察可得依旧为双重循环,分别循环n/2次,(n-i)/2次,此时时间复杂度为 O((n-i)/2 × n/2 × 1),即 O(n^2)。
可见两种算法的时间复杂度其实是一致的,并无差别。
测试数据 a. 处理不同分布方式整型(int)数据的测试结果如下图 2.1.6:
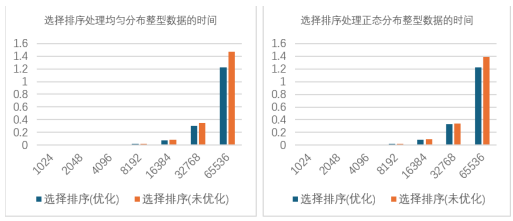
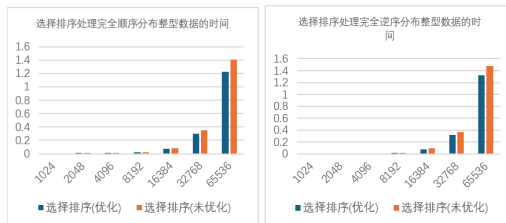
对整型数据测试结果的分析:
对于均匀分布和正态分布的整型数据,优化方案与基础的选择排序算法运行时间差距 不大,但优化后的总是略强于基础方案,减少了运行时间 b.处理不同分布方式浮点型(double)数据的测试结果如下图 2.1.7:
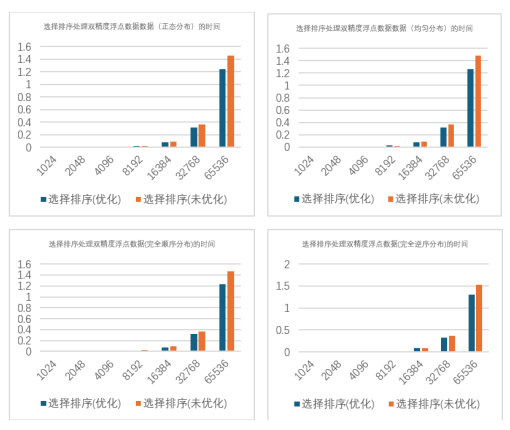
图 2.1.7
对双精度浮点数据测试结果的分析:
对于均匀分布和正态分布的双精度浮点数据,优化方案与基础的选择排序算法运行时 间差距不大,但优化后的总是略强于基础方案,减少了运行时间 ,总的来看,在什么情况 下,优化后的算法总是强于基础版的。
2.2 多种排序算法的联合测试
多种排序算法及其优化算法在不同的数据类型(整型,浮点型),不同的数据规模
(从 1024 到 32768),不同的数据分布(正态分布,均匀分布,完全顺序分布,完全逆序 分布)下的测试数据如下图 2.2.1 和图 2.2.2 所示:
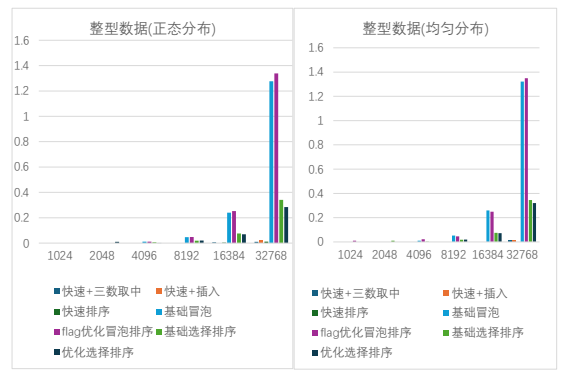
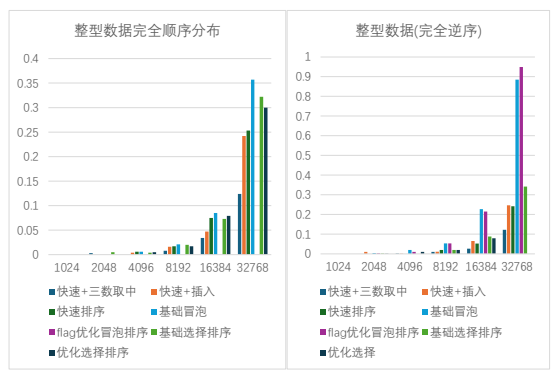
图 2.2.1
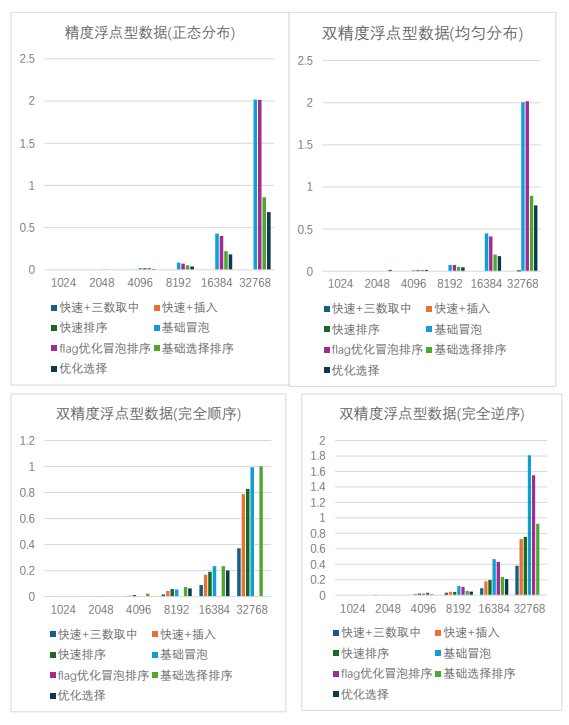
图 2.2.2
根据上述数据分析可知,快速排序算法在数据量较大时相比于其他两种排序算法表现 出明显的优势(尤其是在正态分布和均匀分布时),快速排序的两种优化方案中,快速排 序+三数取中的优化方式表现更为突出,可以大幅降低运行时间。冒泡排序时三种算法中 平均耗时最长的一种排序算法,采用标记法(flag)优化后也不能将运行时间减少到到其 他两种算法的平均水平,且在某些情况下冒泡排序的优化方案并没有起到稳定的作用。选 择排序的优化方案可以稳定的在不同的数据环境下优化程序运行时间。
2.3 三种经典排序算法稳定性分析
对稳定性的理解:假定在待排序的记录序列中,存在多个具有相同关键字的记录, 若经过排序,这些记录相对次序保持不变,即在原序列中 r[i]=fj],且 r[i]在 r[i]之前, 而在排序后的序列中,r[i]仍在 r[j]之前,则称此排序算法稳定:否则称为不稳定。


从理论上来看,快速排序在中枢元素和 a[j]交换的时候,很有可能把前面的元素的稳 定性打乱,所以快速排序是一个理论上就极不稳定的排序算法,不稳定发生在中枢元素和 a[j]交换的时刻,从此实验结果来看,当数据集为 1024 和 65536 时,都存在顺序错乱的情 况,故快速排序为较前面两种排序方式稳定性更低的排序方法。
3. C-字符串数组排序研究
3.1 思考题
1. 下面的测试函数中
(1) 请思考然后进行程序验证 sizeof(strA), sizeof(strB), sizeof(strC), sizeof(strD)各为多少字 节,这些字节位于内存什么区域(代码区、全局数据区、栈区、堆区)?
答:sizeof(strA)为 300,sizeof(strB)为 60,sizeof(strC)和 sizeof(strD)均为 4。
由于 strA 是一个二维字符数组,而二维字符数组的大小由其所有元素的总字节数决定,包 括所有字符串常量及数组本身所需的存储空间。且 strA 因为其大小一开始就定好了所以其 存储在栈内存中,其存储的字符串常量都直接在代码段(常量池)。由于 strB 是一个指针 数组,指针数组的大小取决于数组中指针的数量乘以每个指针的大小。strB 中的每个指针 指向一个字符串常量,故 strB 本身存储在栈内存中。而因为 strC 和 strD 都是指向指针 的指针,并且在初始化时被赋予了 NULL 值,即它们目前并未指向有效的内存位置。这 些指针本身存储在栈内存中。
(附加解释:由于 strB 中的指针所指向的常量字符串是存储在常量池里的,而 strcmp()是 交换指针,因此 BubbleA()能对 strB 排序。但 BubbleB()不能对 strA 排序。)
(2) strA、strB、strC、strD 联系的 C-字符串数组的内容存储在内存的什么区域?它们的读/
写属性(是否可读、可写)如何?
答:strA 中的字符串常量存储在代码区,是只读不可修改的,而 strB 中的指针存储在栈 上,指向的字符串在静态数据区,也是只读不可修改的,而 strC 和 strD 指向可以是任意内 存区域,其读写属性取决于所指对象的具体存储区域及其本身是否被分配了可写的内存空 间。
2.设计 Bubblea,Bubbleb 两个函数之前,思考
(1) 如何比较两个字符串的内容?
答:通过 ASCⅡ码即字典进行比较。
(2) 存储在什么区域的字符串能交换其内容?
答:只有存储在栈和堆区的字符串才能交换其内容。
(3) 若不能交换字符串的内容,排序操作中交换什么?
答:通常会交换指向字符串的指针,而不是交换字符串内容本身。
3.GetStringsA 和 GetStringB 函数的第一个形式参数为什么需要用到三级指针,如果
仅用二级指针会怎样?
答:因为需要在函数内部修改一个指针的指向,而这个指针本身是在函数外部定义和初始 化的,即希望函数能够改变指针本身所指向的地址。如果仅使用二级指针,函数只能修改 指针指向的内存块的值,而无法改变指针本身指向的地址。代入此题的情况也就是 在 GetStringsA 函数中使用三级指针 (char ***dest),使得函数能够动态分配内存,并在函 数内部修改 dest,确保函数执行后分配的内存在函数外部仍然可以访问。 #GetStringsA1 函数应该如何使用?
答:与 GetStringsA 不同的是,GetStringA1 有返回值,而 GetStringA 无返回值,而是直接 通过指针修改 dest。因此在调用此函数的时候,需要如下:(即先接受返回值再在结束时 释放内存)
char **result = GetStringsA1(source, n); for(i=0; i<n; i++) {
free(result[i]);
} free(result);
4. Freestrings 函数的形式参数为什么需要用到三级指针?
答:当动态分配的内存是通过三级指针来管理时,函数通过操作三级指针可以直接访问和 释放指向字符串数组的指针,以及数组中每个字符串的指针。在释放内存后,为了避免出 现悬空指针的情况,需要将原始指针设为 NULL。通过使用三级指针作为参数,函数可以 修改传入指针的指向,将其置为 NULL。
3.2 不同存储方式能够进行/不能进行的操作方法
1、对于 BubbleA:使用数组指针,需要更多内存以及复制操作,对数组的长度有严格要 求。在操作即排序过程中需要频繁地复制字符串内容到 temp 数组中,涉及更多的内存读 写操作。当 NUM 过大的时候,使用 BubbleA 可能不是很方便。但 BubbleA 可以处理 strA,也能处理 strB
2、对于 BubbleB:使用指针数组,内存消耗较少,更适合处理不定长字符串或者长度不同 的字符串数组。在操作过程中只需要交换指针,减少了内存操作,可能在大量数据排序时 效率稍高。由于 strA 中的字符串存储在常量池中,所以 BubbleB 不能处理 strA,只能处理 strB。
——————————————————————————————————————————————
3、对于字符串数组,使用数组指针通常更适合进行插入和删除操作,因为数组指针可以指 向数组中的任意位置,,使得插入操作更为方便,且如果字符串长度可变或需要动态扩 展,数组指针可以更容易处理这种情况。相比之下,指针数组虽然在某些方面提供了更多 的自由度,但在插入和删除操作上可能会涉及到多个指针的协调,不如数组指针直接和简 洁。
3.3 补充
对于原 StrCmp(const char *str1, const char *str2)函数来说,进行了一点小小的修改,原函数 为:
1 | int StrCmp(const char *str1, const char *str2) {//修改前的原函数 unsigned char *p1 = (unsigned char*)str1; unsigned char *p2 = (unsigned char*)str2; while(*p1 && *p2 && *p1++==*p2++) |
如此会出现一个问题,即在于 return 语句,它试图在增加 p1 和 p2 指针后立即返回比 较结果。然而,在循环内部已经对 p1 和 p2 进行了自增操作。这意味着当循环结束时, p1 和 p2 指向的字符已经不相等,但返回语句仍然在比较循环开始时的字符。这种情况 下,返回的比较结果可能是不正确的,特别是对于长字符串或者包含多字节字符的字符 串。
修改后函数为:
1 | int StrCmp(const char *str1, const char *str2) { //修改后的函数 unsigned char *p1 = (unsigned char*)str1; unsigned char *p2 = (unsigned char*)str2; while(*p1 && *p2 && *p1==*p2) |

由上图 3.1 可知修改之后,strcmp()和 StrCmp()函数具有同样的功能 附 BubbleA 和 BubbleB 的程序:
1 | void BubbleA(char (*str)[NUM],int size) |
4. 小组分工及组员感想
4.1 小组分工说明
周宸宇:实现并优化快速排序,测试,并进行分析。整合小组成员负责的三种排序算法, 对排序算法及其优化方案联合测试,制作图表分析数据,论文撰写,论文排版。
刘思齐:不同存储方式的 C-字符串排序及思考题、三种排序的稳定性分析。
唐海棠:实现并优化冒泡排序,测试,并进行分析。
彭家正:实现并优化选择排序,测试,并进行分析。
5. 结语
通过深入参与这门实训课程,我们系统地学习了经典的排序算法及其优化策略。在持 续探索与解决问题的过程中,我们不仅提升了编程技能与算法应用能力,更为后续的专业 学习奠定了坚实的基础。同时,此次实践机会也让我们在团队协作与人际沟通方面得到了 充分的锻炼。在大家的共同努力与协作下,我们顺利完成了实训任务,实现了知识与技能 的双重提升。
致谢 感谢任课老师的谆谆教诲,同时也感谢小组内所有成员的辛勤付出,也相信我 们可以通过此次实训打开进入计算机学院的大门。
参考文献
[1]CSDN 技术社区 https://blog.csdn.net/chuxinchangcun/article/details/133363649
[2]CSDN 技术社区 https://blog.csdn.net/qq_38289815/article/details/82718428
[3]CSDN 技术社区 https://blog.csdn.net/Kevinnsm/article/details/114448053
[4]CSDN 技术社区 https://blog.csdn.net/fzhhsa/article/details/103113915





